Платформа обучения модели Maixhub позволяет быстро обучить нужную модель ИИ, при этом не нужно создавать какую-либо среду обучения и запускать код, нужно просто выбрать тип обучения и загрузить помеченный набор данных. Maixhub автоматически обучит модель и отправит результаты по электронной почте.
На данный момент доступны два типа обучения:
1. Классификация объектов: Определение категории, к которой принадлежит изображение, например яблоко или чашка, без координат. Как показано ниже, вероятность того, что это яблоко, составляет 0,8.

2. Обнаружение объекта: Определение положения объекта на изображении и вывод координаты объекта и размера объекта (т.е. кадрирование распознанного объект). Как показано на рисунке ниже, вероятность того, что яблоко будет яблоком, равна 0,8, если оно обнаружено и его местоположение отмечено рамкой.
 I Постановка задачи
I Постановка задачи
1. Выбор тип обучения.
Выберите «Классификация объектов», если нет необходимости определять положение объекта, иначе выберите «Обнаружение объекта».
Подготовка наборов данных для обнаружения объектов более сложна, чем классификация, поэтому рекомендуется использовать классификацию объектов, если вы впервые используете Maixhub, чтобы сначала ознакомиться с процессом.
2. Выбор классов.
Необходимо определиться с количеством и названием классов. Внимание: имя класса (метка) может использовать только английский символ и символ нижнего подчеркивания.
3. Выбор разрешения изображения.
Разрешение изображения также очень важно при их получении, обучении или использовании, поскольку модель может быть непригодной для использования или может иметь низкую точность распознавания.
Maixhub поддерживает в настоящее время следующие разрешения изображений:
1. Классификация объектов: 224x224 (рекомендуется)
2. Обнаружение объектов: 224x224 (рекомендуется), 240x240
Другие разрешения не пройдут обучение (рекомендуемое разрешение более точное).
4. Определение количество изображений в наборе данных. То есть необходимо определить количество изображений для каждой категории, чтобы облегчить быстрый сбор изображений и получить точный результат в дальнейшем. Также должны выполняться требования Maixhub по количеству изображений:
1. Классификация объектов: не менее 40 изображений на класс.
2. Обнаружение объектов: не менее 100 изображений на класс.
5. При этом следует обратить внимание, что размер загруженного zip-файла не может превышать 20 МБ.
II Сбор изображений
Цель состоит в том, чтобы собрать изображения с заданным разрешением.
Есть несколько способов собрать изображения:
1. Сделать снимок с желаемым разрешением и сохранить его на на SD-карту с помощью платы разработки (рекомендуется авторами инструкции).
2. Сделать снимок камерой телефона, затем используя инструмент предварительной обработки, сжать фотографии до необходимого разрешения, и обязательно проверить данные вручную после обработки, иначе это может повлиять на точность обучения.
3. Использовать существующие изображения, например общедоступные наборы и обработать их до необходимого разрешения с помощью инструментов предварительной обработки.
III Маркирование набора данных
Для классификации объектов не требуется маркирование данных.
Для детектирования объектов необходимо маркирование исходных данных. То есть, с помощью специальной программы необходимо выделить область на изображении, которую занимает объект определенного класса и присвоить этой области соответствующую метку класса.
Внимание! Перед тем, как пометить изображения, ещё раз необходимо убедиться, что разрешение правильное.
Для аннотации доступны следующие два инструмента.
1.
Vott
2.
labelimg
Далее показан пример маркирования данных в программе Vott.
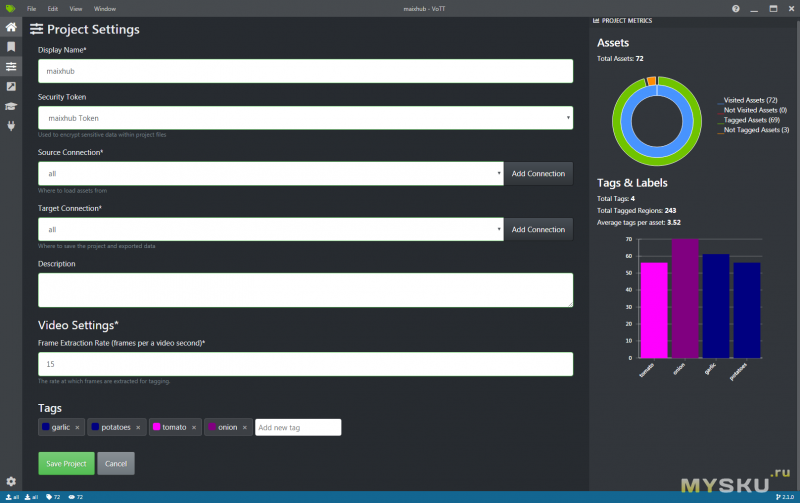
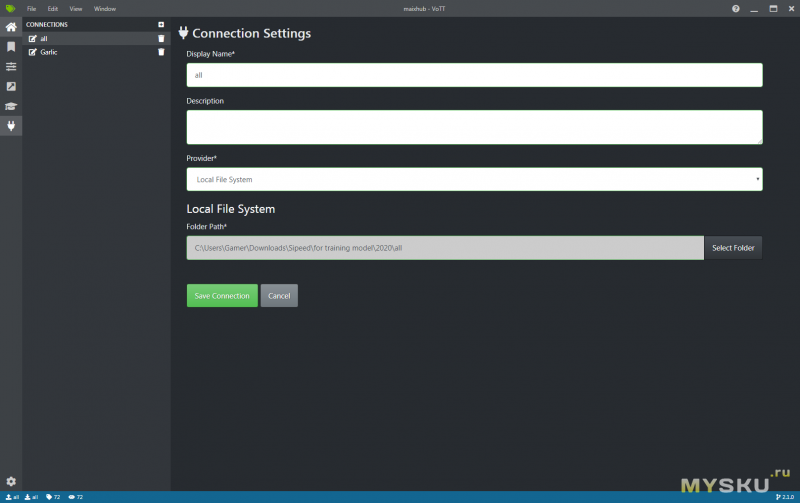
Во-первых необходимо создать проект и создать соединение с папкой ввода/вывода данных. При создании проекта необходимо добавить метки классов.
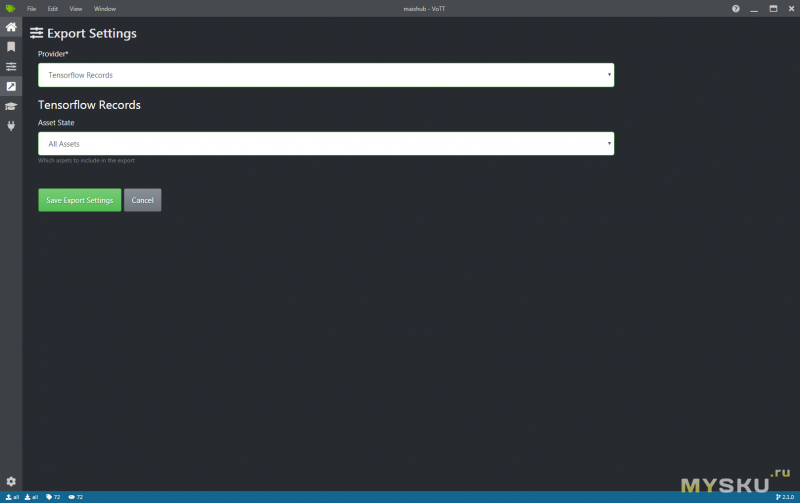
Затем в настройках экспорта необходимо выбрать формат TensorFlow Records.
Далее необходимо непосредственно аннотировать данные, для этого нужно выделить область, занимаемую объектом и выбрать метку класса, к которому он относится.
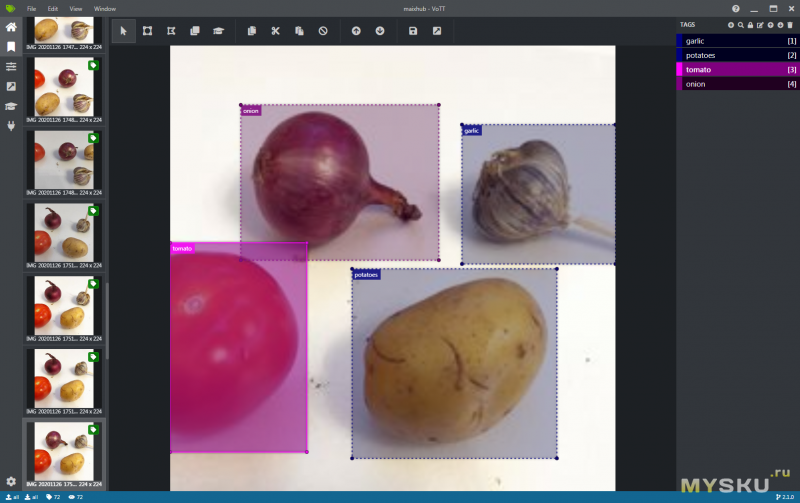
После аннотирования необходимо нажать кнопку «Экспорт», чтобы экспортировать файл TensorFlow Record.
Будет создана необходимая структура каталогов файлов, обратите внимание, что требуется файл tf_label_map.pbtxt, который создается автоматически, не меняйте его вручную.
IV Упаковка набора данных
Набор обработанных данных необходимо упаковать с помощью zip, другие форматы пока не поддерживаются, размер архива не должен превышать 20 МБ.
Классификация объектов
Один класс на папку, имя папки (метка) — это имя класса

Обнаружение объекта
Пример выходной файловой структуры Vott
 V Загрузка наборов данных и начало обучения
V Загрузка наборов данных и начало обучения
Создайте задание на обучение на
www.maixhub.com/mtrain.html
— Выбрать тип обучения
— Введите адрес электронной почты, чтобы получать результаты, включая успешные (файлы модели и т. Д.) И неудачные (причина отказа) результаты.
— Если требуется машинный код (пропустите этот шаг, если нет):
Предупреждение: из-за необходимости шифрования модели запуск key_gen.bin всегда будет отключать порт JTAG и записывать одноразовый ключ AES. Перед записью убедитесь, что он не влияет на вашу разработку. (Если вы не используете JTAG для отладки разработки или просто используете MaixPy для разработки, это не повлияет на вашу разработку).
— Скачать прошивку key_gen key_gen_v1.2.zip
— Скачать kflash-gui
— Записать прошивку key_gen с помощью kflash-gui
— Открыть терминал, сбросить плату, в терминале будет получено сообщение:

где 6f80dccbe29 ********** cc7e9d69f92 — это машинный ключ платы разработчика
— Загрузить набор данных
— Нажать кнопку создания задачи.
VI Результаты обучения и способы использования
Результаты обучения (успех или неудача) будут отправлены на ваш электронный адрес. Это zip-архив. Разархивируйте его и внимательно прочтите README.txt, в нем объясняется, как его использовать на английском и китайском языках.
По умолчанию, если установлена последняя версия прошивки, необходимо скопировать все полученные файлы в корневой каталог SD-карты, выключить питание и вставить SD-карту в плату для разработки, затем включить питание и скрипт boot.py будет запущен автоматически!
Если вам нужно поместить модель во флеш-память для этого необходимо записать файл m.kmodel во флеш-память с помощью K-Flash GUI и в программе соответственно изменить адрес загрузки модели.









Вопос зачем такая плата (вещь в себе) нужна если легко ее обучить не получается и применить больше никуда нельзя? Малину хоть потом пристроить можно.
Я видел вполне рабочую реализацию распознавания показаний, просто у меня ввиду описанных причин хорошего результата не получилось. А вариантов использования помимо озвученных достаточно, как и у других платформ: различные роботы, автоматические кормушки, эмуляторы игровых консолей и т.п.
Реальное применение с огромным выхлопом в баксах — сортировка зерна, круп, картошки, яблок, и так далее. Например грязная гречка стоит примерно 2к рублей за тонну — поросятам самое то. Но фермеры уже давно научились её очищать — результат в магазине.
зы — фермеры что отстали от поезда — уже давно разорились.
Почти все характеристика будут в разы лучше.
Памяти будет не жалкие мегабайты, а гигабайты. Процессор явно быстрее. А уж про камеру я не говорю.
Плюс спать все мобильники умеют правильно. Код хочешь юзай android, хочешь пиши бинарные модули.
Главное найти мобильник, для которого есть инфа о используемых контроллерах дисплея и камеры,
чтобы не заниматься реверсингом драйверов камеры, дисплея и прочей периферии.
а где почитать про это?
PS а если фотографию к камере поднести?
))))
Фотку тоже распознает. Но делался сервис по открытию калитки от добрых людей. Кому надо — через забор перелезет, там у меня колючей проволоки под током нет )
А вот если есть силы, навыки и время сделать в формате — купите вот это, сделайте в точности как я вот это и оно станет:
— отличать вашу мордулица от других и сообщать об этом в умный дом
— считать количество людей прошедших мимо камеры
— различать номера машин
— различать форму и цвет машины для детекции определённой (понятно что марка и цвет могут совпасть и тогда ой)
Вот тогда вот вообще хорошо будет.